TL;DR
If you are responsible for an AI deployment in 2026, the choice in front of you is not whether to do AI governance. You already have one. The harder question is whether your governance stack also blocks unsafe prompts and outputs at request time, or whether it only documents that you know it should.
That distinction is what splits the AI governance platform market today. Governance-only platforms — Credo AI, IBM watsonx.governance — give you a policy plane: an AI registry, control mapping, monitoring dashboards, and attestation reporting. Runtime enforcement platforms — Prisma AIRS after Palo Alto Networks' acquisition of Protect AI, Check Point's acquisition of Lakera, ABV, and a small set of others — sit inline with the LLM request and decide, per call, whether to block, modify, or regenerate.
Both layers do useful work. They do not do the same work. The argument of this article is narrow: for buyers operating high-risk systems under the EU AI Act, monitoring-only governance does not satisfy the technical obligations the regulation imposes. Use this article to align the AI risk officer, the CISO, and the platform engineering lead before the next audit cycle on what each layer actually does, and which one your current stack is missing.
Why AI governance became a confusing category in 2025
For most of 2023 and 2024, "AI governance platform" meant one thing in enterprise procurement: software that helped an organization classify AI use cases, map them to a control framework, and produce evidence for auditors. Credo AI built the category. IBM watsonx.governance packaged it for the Global 2000. The work was real, and it lived above the request path.
Then four things happened in roughly twelve months. Palo Alto Networks closed its Protect AI acquisition in July 2025, folding model scanning, posture management, AI red teaming, runtime protection, and AI agent security into Prisma AIRS as five pillars of one stack. Check Point announced its acquisition of Lakera in September. SentinelOne acquired Prompt Security and Cato Networks acquired Aim in adjacent windows. At roughly the same time, Helicone announced it was joining Mintlify after processing 14.2 trillion tokens for 16,000 organizations — the strongest available market signal that pure LLM observability is not a viable standalone category. It gets absorbed.
What survived as separate enterprise purchases were two distinct things: policy and audit work (the governance plane) and request-time controls (the runtime plane). The reason the category looks confusing is that vendors on both sides keep using the word "governance" for what they sell. They mean different layers.
Four functions every AI governance buyer conflates
Before any comparison is useful, separate the four functions an enterprise AI program actually has to perform.
- Policy capture. Document the AI estate, classify use cases against an internal taxonomy and an external framework, and produce a defensible record of decisions. This is where Credo AI and IBM watsonx.governance live, and they do it well.
- Monitoring and evaluation. Trace LLM traffic, score outputs against quality and safety rubrics, and surface regressions. Pure observability platforms grew up here; almost all of them have either consolidated into broader stacks or added enforcement.
- Runtime enforcement. Evaluate inputs and outputs at the request boundary, then block, modify, or regenerate the response. This is what Lakera, Prompt Security, Protect AI, and ABV do. It is the control plane, not the observability plane.
- Audit and attestation. Produce per-request and per-system evidence that maps to a control family — ISO 42001 clauses, NIST AI RMF functions, EU AI Act articles. Governance platforms produce program-level attestation; runtime platforms produce per-decision records.
The four are complementary. The mistake is treating one as a substitute for another. A registry does not block a prompt-injection payload. A guardrail does not produce a board-level attestation by itself.

Governance-only vs runtime enforcement: capability comparison
The capability differences track the four functions above. The rows below name a buyer task and where each side of the market lands on it.
| Capability | Governance-only platforms | Runtime enforcement platforms |
|---|---|---|
| AI use-case registry and inventory | ✓ Native; primary offering | ◐ Limited; typically integrates with a governance platform |
| Policy capture and control mapping (ISO 42001, NIST AI RMF, EU AI Act) | ✓ Native; deep | ◐ Partial; mapped per-decision rather than program-wide |
| Risk identification and classification | ✓ Native | ◐ Limited |
| Monitoring and evaluation dashboards | ✓ Native | ✓ Native for runtime decisions |
| Input filtering (prompt injection, malicious URLs, PII) | ✕ Not native | ✓ Native; inline, per-request |
| Output validation (hallucination, off-topic, sensitive content) | ✕ Not native | Native; inline, per-request |
| Block / modify / regenerate at request boundary | ✕ Not native | ✓ Native |
| Per-request audit log for EU AI Act Article 12 traceability | ◐ Partial | ✓ Native |
| Compliance acceleration and attestation reporting | ✓ Native; differentiator | ◐ Partial; complementary |
| Program-level evidence for board and external auditors | ✓ Native | ◐ Partial |
Credo AI's own product page is precise about this. It markets the runtime tier as "24/7 Runtime Monitoring — Continuous Governance." The word "Monitoring" is doing real work in that sentence. IBM watsonx.governance describes itself as "real-time assurance, visibility and control," and reports outcomes such as Infosys's 150 percent increase in operational efficiency across 2,700 AI use cases and an internal 58 percent reduction in third-party data clearance time, with more than 1,000 models approved for reuse. Those are governance ROI numbers — faster approvals, hygienic inventory — not request-time interception numbers.
Three buyer scenarios where monitoring is not enough
Which side of the market wins depends on the scenario. These three are the most common gates where buyers discover that documentation does not stop a live attack.
- PHI exfiltration through a customer support copilot. A healthcare provider deploys an LLM-backed agent with read access to patient records. A monitoring tool will detect that the assistant returned PHI in a response and flag it for review. It will not redact the PHI before the response leaves the model. For HIPAA-covered traffic and for EU AI Act Article 15 accuracy and cybersecurity obligations across the lifecycle, that distinction is operational, not academic.
- Prompt injection against an agentic workflow. OWASP's LLM Top 10 ranks prompt injection as LLM01 and is explicit that RAG and fine-tuning do not fully mitigate it. A registry entry that says "this agent has tool use" does not prevent a malicious document the agent retrieves from instructing it to invoke the wrong tool. Input filtering and tool-call validation at the request boundary do.
- Third-party SaaS LLMs in the shadow estate. A platform team discovers that thirty internal SaaS apps now embed an LLM feature through the vendor. A governance platform can record them in the inventory. Without a policy decision point on the request path — a gateway or in-app guardrail — there is nowhere to enforce data-class restrictions on what employees can paste in. Monitoring will produce a regret report. Enforcement prevents the leak.
The pattern in all three: monitoring tells you what happened; enforcement changes the outcome at the moment it matters.
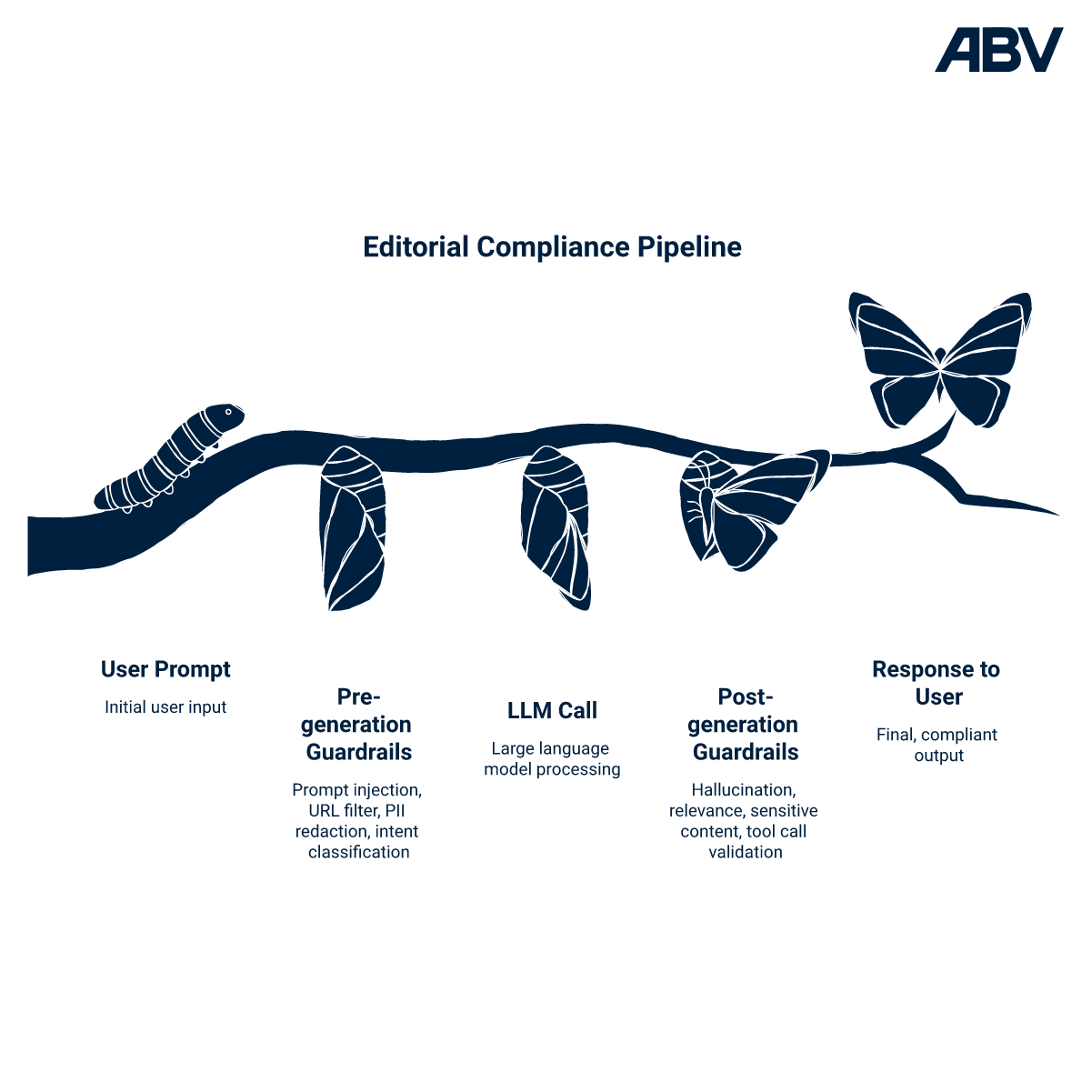
A reference architecture for runtime policy at the request boundary
Runtime enforcement, done well, is not a single guardrail. It is a chained policy decision point — a small set of input checks before the model call and a small set of output checks after it.
The input side, evaluated before the LLM is invoked, typically includes prompt-injection detection, malicious-URL filtering, PII redaction, and topic or intent classification. Most of these can be implemented with cheap rule and classifier checks. The output side, evaluated after the model responds but before the user sees the answer, typically includes hallucination scoring, off-topic detection, sensitive-content filtering, and, for agents, tool-call validation. These tend to require LLM-as-judge calls and are the more expensive half of the chain.
The control logic for each guardrail is binary in effect: pass, block, modify, or regenerate. The orchestrator chains them so an early cheap check can short-circuit a request before more expensive checks run. ABV reports that a typical production chain runs three to seven guardrails, single-guardrail latency stays under 300 milliseconds, and chained pipelines come in under 500 milliseconds end-to-end. Check Point's press release reports that Lakera holds false positives below 0.5 percent without impacting speed or accuracy. These are vendor-stated figures; the architectural point — that the chain is what makes the latency budget achievable — holds independently.
The latency objection to runtime enforcement has not gone away. It has shifted. The question is no longer "can we afford to enforce at request time?" but "which guardrails belong in the chain, and where does each sit?"
Control-family mapping: ISO 42001, NIST AI RMF, EU AI Act Articles 9/12/14/15
The control-family mapping is where the governance-vs-enforcement distinction stops being theoretical.
ISO/IEC 42001:2023 is the first international AI management system standard. It defines an organization-level AIMS — policy, roles, processes, continual improvement. Governance-only platforms cover the AIMS surface cleanly. A monitoring-only tool can satisfy ISO 42001's risk identification and performance evaluation clauses. It does not, by itself, satisfy clauses that require operational controls and active risk treatment. Those expectations are where the runtime layer becomes necessary.
The NIST AI Risk Management Framework structures AI risk work around four functions: Govern, Map, Measure, and Manage. NIST is voluntary, not enforceable. Govern and Map are governance-platform native. Measure overlaps both layers. Manage — the function that requires acting on identified risks — is where runtime enforcement is the operative tool.
The EU AI Act is where the gap closes hard. Article 9 mandates a continuous risk-management system across the lifecycle of every high-risk AI system. Article 12 requires the system itself to technically allow for the automatic recording of events — logs — over its lifetime. Article 14 requires the system to be designed so that natural persons can effectively oversee it during use. Article 15 imposes accuracy, robustness, and cybersecurity obligations across the full lifecycle.
A monitoring-only platform can describe the Article 9 risk management program and the Article 14 oversight roles. It cannot, on its own, produce the per-request automatic logs Article 12 demands at the system level, intercept on behalf of the human overseer Article 14 names, or satisfy the request-time half of Article 15's accuracy and cybersecurity duties. Those technical obligations live below the management system, on the request path. That is the load-bearing reason this article exists.
ENISA's Multilayer Framework for Good Cybersecurity Practices for AI already treats AI-specific cybersecurity as its own layer above traditional security foundations. European regulators have effectively codified the governance-vs-enforcement split as separate disciplines, and the buyer org chart usually mirrors it: GRC owns the AIMS, security owns the runtime.
A buyer evaluation checklist
A short checklist for an enterprise evaluation, ordered by what tends to fail first:
- Has the team mapped its AI inventory to ISO 42001 control families and to the four NIST AI RMF functions?
- For every high-risk system, does the current stack produce per-request automatic logs sufficient for Article 12 traceability, or only retrospective reconstructions?
- Where in the request path can a human overseer intervene before an output reaches a user, per Article 14?
- Which OWASP LLM Top 10 attack classes have an enforced control, not only a documented one?
- For llm guardrails on agentic workflows, is tool-call validation part of the chain or assumed?
- For ai red teaming, is the program continuous and tied back into the runtime policy, or a one-off pre-deployment exercise?
- If you removed the governance platform for a quarter, would the request-time defenses still work? If you removed the runtime layer, would the audit pack still be defensible?
- Is the data residency and certification posture of your runtime layer at parity with your governance layer? Buyers in regulated industries do not have the option of an enforcement layer that breaks the residency story.
Independent advisors at Ankura Consulting recommend deploying runtime guardrails, enforcing continuous red teaming, and integrating AI telemetry with existing policies. Stanford HAI's 2026 AI Index frames the same point at the population level: a widening gap between what AI can do and how prepared organizations are to manage it. The checklist above is what closes the gap on a single deployment.
Where ABV fits
ABV is the runtime enforcement layer that sits alongside an AIMS, not a replacement for one. We sit inline with the LLM request, chain three to seven guardrails per request path, and emit per-decision audit evidence that maps to ISO 42001 control families and to EU AI Act Article 12 record-keeping. We report sub-300-millisecond single-guardrail latency and chained pipelines under 500 milliseconds end-to-end; treat those as vendor-stated figures and benchmark them inside your own request budget.
On the credibility posture buyers in this audience tend to ask about: ABV is ISO 27001 audited annually, ISO 42001 aligned, and operates US, EU, and HIPAA-eligible regions with DPA and BAA available. If you already have Credo AI or IBM watsonx.governance running, ABV slots underneath as the request-path defense those platforms are not designed to be. If you do not yet have an AIMS, run GenAI Risk Protection alongside the ISO 42001 program your GRC team is standing up. The two layers settle different audit conversations; both need to be answered.
FAQ
What is the difference between AI governance and runtime enforcement?
Governance covers policy capture, control mapping, monitoring, and attestation. Runtime enforcement evaluates inputs and outputs at the request boundary and blocks unsafe traffic. Standards including ISO 42001 and the NIST AI RMF distinguish risk identification controls from risk treatment controls. Runtime enforcement is the active-treatment layer that monitoring alone does not satisfy.
What is an AI governance platform?
An AI governance platform is software that helps organizations identify, classify, and document AI risks against a control framework such as ISO 42001, the NIST AI RMF, or the EU AI Act. The category historically focused on policy capture and reporting. In 2025 it expanded to cover runtime input/output enforcement and audit-log evidence for high-risk systems.
Can a monitoring-only AI governance tool meet ISO 42001 requirements?
Monitoring-only tools can satisfy ISO 42001 risk identification and performance evaluation clauses, but they do not by themselves satisfy clauses that require operational controls and active risk treatment. Buyers operating high-risk systems under the EU AI Act also need Article 12 record-keeping evidence that monitoring-only tooling rarely produces at the request boundary.
What is the difference between Credo AI, IBM watsonx.governance, and runtime enforcement platforms?
Credo AI and IBM watsonx.governance focus on policy, control mapping, model inventory, and attestation reporting, and integrate with monitoring tools. Runtime enforcement platforms add a policy decision point at the request boundary that blocks prompt injection, unsafe outputs, and data exfiltration in line with the request, then emit audit evidence tied to standard control families.
How does runtime enforcement satisfy EU AI Act Article 12 record-keeping?
Article 12 requires high-risk AI system providers to keep automatically generated logs sufficient to ensure traceability. Runtime enforcement emits a per-request decision record that maps each input, policy outcome, and output to a control family, providing direct Article 12 evidence rather than retrospective reconstructions assembled from disconnected logs.
Next steps
If you are scoping the runtime layer next quarter, start with the request paths in your highest-risk system. ABV's GenAI Guardrails page documents the chained-pipeline pattern; Agent Observability covers the agentic case; the Trust Center covers the certification and residency posture; a demo is the fastest path to a working session against your own architecture.


