GenAI App Observability
ABV provides a complete solution to safeguard, monitor, and analyze in-house LLM apps.


Control GenAI across your entire org with ABV



ABV operates as the control plane for production GenAI apps
Providing visibility, safety, and compliance across your entire stack
Application Runtime
- GenAI apps & agents
- User interfaces
- Production workflows & pipelines
- Input/Output Guardrails
- Session Tracking
- End-user Feedback
- Automated Evaluations
Technology Provider
Orchestration
- LLM orchestration frameworks
- Workflow engines
- Agent coordination
- Distributed Tracing
- Prompt Management
- Performance Monitoring
- Prompt Experiments
Technology Providers
Models
- Foundation models (LLMs)
- Fine-tuned models
- Model serving
- Token & Cost Tracking
- LLM Governance
- Model Performance Tracking
- LLM Gateway
Technology Providers
Data & Infrastructure
- Vector databases
- RAG infrastructure
- Embedding pipelines
- Data Lineage
- PII Masking
- Audit Logs
- Infrastructure Performance Tracking
Technology Providers
Cross-Stack Observability & Governance Layer
ABV across industries
ABV helps enterprises and governments deploy reliable, trustworthy LLM applications at scale.
Education Services
Protect sensitive student data (PII) and academic content (IP) while monitoring user feedback to maintain trust in AI-powered learning platforms.
Travel and Hospitality
Measure hallucination and toxicity levels to ensure LLM applications are correct, safe, and secure
Government & Public Sector
Monitor AI systems for bias and fairness to ensure equitable public service delivery. Maintain complete audit trails for transparency.
Telecommunications
Measure answer quality metrics — including relevance, factual accuracy, and source grounding — for AI-assisted employee training.
Legal Services
Track AI-assisted legal research and protect client confidentiality with automated PII detection and secure audit trails.
Financial Services
Validate that internal LLM tools deliver accurate data to investment analysts and support reliable financial forecasting.

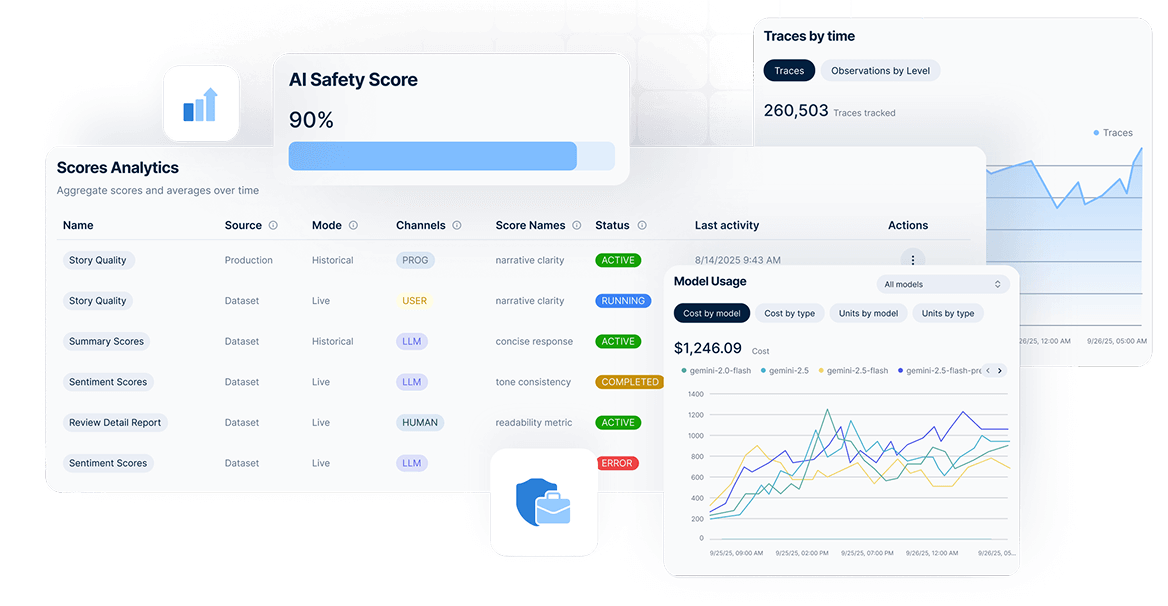
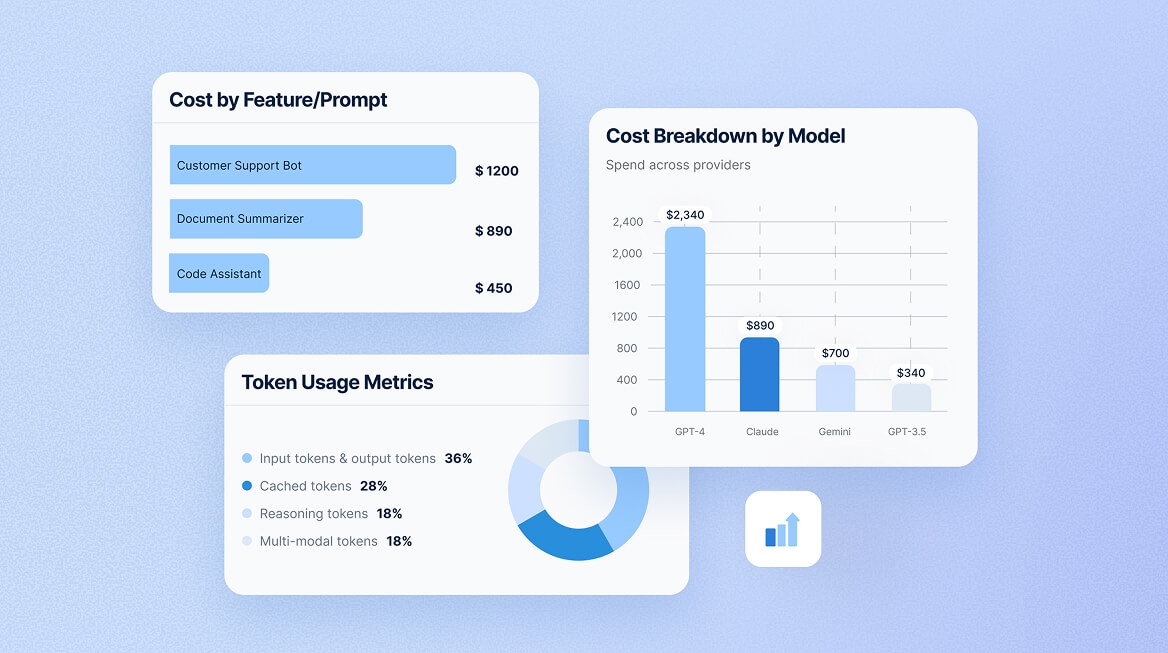
Identify Cost Drivers Across Your LLM Stack
Reduce expenses by as much as 40% through intelligent usage monitoring.
ABV analytics surface high-cost operations in real-time, helping teams switch to cheaper models for simple tasks, implement caching strategies, and set budget alerts before overages occur.
Questions & Answers
GenAI App Observability is a complete governance solution that unifies all critical lifecycle steps for both in-house and external GenAI apps, letting you focus on creating value.
LLMs are generative AI systems that create new content (text, code, images) rather than just classifying or predicting from fixed options. Traditional AI systems learn patterns from labeled data to make specific predictions, while LLMs understand and generate human-like language based on vast training data. This generative capability introduces unique challenges: non-deterministic outputs, hallucinations, prompt injection risks, and compliance complexities that require specialized observability and governance.
GenAI applications face distinct challenges that traditional monitoring can't address: debugging non-deterministic LLM behavior, tracking unpredictable API costs, ensuring compliance with AI regulations, preventing harmful outputs, and measuring quality when responses vary. Observability captures full context for every interaction—enabling you to reproduce bugs, analyze cost drivers, maintain audit trails for regulators, and systematically improve quality through evaluations.
Guardrails are automated safety checks that validate LLM inputs and outputs before they reach users or your model. They detect toxic language, biased content, PII leaks, prompt injection attempts, and policy violations in real time. By running validation checks that take milliseconds (rule-based) or seconds (LLM-powered), guardrails prevent harmful content from reaching production while maintaining compliance with HIPAA, GDPR, and organizational policies.
Guardrails analyze content through two approaches: rule-based checks (pattern matching, schema validation) that return instant binary results, or LLM-powered analysis that understands context and nuance but takes 1-3 seconds. Each validation returns a status (pass, fail, or unsure), confidence score, and explanation. You then decide whether to allow the content, block it, flag for human review, or regenerate based on your risk tolerance.
Track three core categories:
Quality User feedback, model-based scores, human annotations to measure how well your LLM serves users.
Cost and Latency Token consumption, API costs, request duration, time-to-first-token to optimize the performance-cost tradeoff.
Volume Trace counts, token throughput, user activity to understand usage patterns). Slice these metrics by user, feature, model, and version to identify optimization opportunities.
