
If you are mid-evaluation on a GenAI guardrail stack, the OWASP Top 10 for LLM Applications looks like the cleanest way to score vendors. It is not. The taxonomy enumerates ten risk categories — LLM01 Prompt Injection through LLM10 Unbounded Consumption — but ticking ten boxes on a vendor slide tells you nothing about where the runtime decision happens, what the audit log will look like when your reviewer opens it, or which categories the vendor cannot actually enforce.
The procurement-grade question is narrower. For each OWASP class, does the vendor block the event at the request boundary, response boundary, agent loop, retrieval pipeline, or gateway — and is there a per-request audit signature your reviewer can pull? Asked class by class, "OWASP coverage" stops being a marketing claim and becomes a mapping you can defend in an RFP. This guide does that mapping, names the standards reference your review will cite, and lists the three classes where our runtime plane does not sit on the load-bearing control.
The six criteria every LLM security mapping should pass
Before scoring a vendor against the OWASP LLM Top 10, fix the criteria. The brief is the same for every class.
- OWASP-anchored definition. The vendor cites the OWASP LLM01-LLM10 primary source, not a paraphrase. The OWASP project pages are the reference.
- Runtime boundary named. The control enforces at a specific point — input, output, agent step, retrieval, or gateway. Monitor-and-alert without enforcement leaves your risk and compliance posture exposed.
- Audit-log signature. Every blocked or modified event produces a per-request log entry your reviewer can extract — what NIST expects, what the EU AI Act assumes, what an internal audit needs to defend the control.
- Standards mapping. The control links to a regulator-grade obligation: a NIST AI 600-1 action ID, EU AI Act article, ISO 42001 management-system control, or ENISA / ICO guidance. "We map to NIST" without an action ID is not a mapping.
- Configurable action policy. The buyer can choose Block (reject), Modify (sanitize), or chain multiple guardrails. Uniform action plans force LLM02 sanitization to behave like LLM07 hard-stop. They should not.
- Honest gap statement. Where the vendor does not enforce a class natively, the gap is named, scoped, and routed to a compensating control. Silent gaps are the worst outcome of a security review.
A class that fails criteria one through five is not actually covered. Criterion six separates a procurement-grade vendor from a brochure.
OWASP LLM Top 10 to ABV runtime controls and standards
The table summarizes the mapping. Per-class detail and primary citations follow.
| OWASP class | ABV runtime surface | Runtime boundary | Primary standards anchor |
|---|---|---|---|
| LLM01 Prompt Injection | Guardrails (rule + LLM chain) | Input + retrieval | NIST MS-2.7-001; EU AI Act Art. 15(5) |
| LLM02 Sensitive Information Disclosure | Guardrails (PII, secrets); App Observability | Input + output | NIST MP-4.1-001; ICO Art. 22 |
| LLM03 Supply Chain | Not natively enforced (gap) | n/a | NIST GV-1.2-002; ISO 42001 PDCA |
| LLM04 Data and Model Poisoning | Not natively enforced (gap) | n/a | EU AI Act Art. 15(5); ENISA AI-specific layer |
| LLM05 Improper Output Handling | Guardrails (code injection, output filter) | Output | NIST MS-2.7-001 |
| LLM06 Excessive Agency | Agent Observability + Guardrails | Agent loop | OWASP LLM06 complete mediation |
| LLM07 System Prompt Leakage | Guardrails (system-prompt detection) | Output | NIST MP-4.1-001 |
| LLM08 Vector and Embedding Weaknesses | Partial (vector-store hardening gap) | Retrieval | EU AI Act Art. 15(5); ENISA |
| LLM09 Misinformation | App Observability (evaluations, tracing) | Orchestration | NIST GV-1.2-002 |
| LLM10 Unbounded Consumption | Risk Protection + gateway controls | Gateway | NIST AI 600-1 §2.9 |
Our runtime surface sits on at least seven of the ten classes — LLM01, LLM02, LLM05, LLM06, LLM07, LLM09, LLM10. LLM03, LLM04, and the vector-store-hardening side of LLM08 require controls upstream of the runtime.
Walking the attack classes
LLM01 Prompt Injection
LLM01 is a vulnerability in which user prompts alter the model's behavior in unintended ways, with explicit direct (user input) and indirect (retrieved documents, tool outputs, RAG context) variants. Vendors that only inspect the prompt envelope miss indirect injection. OWASP's mitigation list pairs constrained behavior, output validation, input/output filtering, privilege control, segregated external content, and adversarial testing.
Our LLM guardrails cover direct and indirect injection at the input and retrieval boundary in two tiers: a rule-based tier under 100 milliseconds for synchronous chat and search paths, and an LLM-chain tier under 300 milliseconds for the slower judgment classes — LLM jailbreak detection and indirect injection with semantic intent.
Audit-log signature: detection class (direct injection / jailbreak / indirect injection), matched rule or model verdict, action taken, upstream source if indirect.
Standards anchor: NIST AI 600-1 MS-2.7-001 lists prompt injection in its baseline vulnerability set; EU AI Act Article 15(5) requires technical measures against inputs designed to cause model error.
LLM02 Sensitive Information Disclosure
LLM02 is more than PII. OWASP splits it into PII Leakage, Proprietary Algorithm Exposure, and Sensitive Business Data Disclosure, and references CVE-2019-20634 ("Proof Pudding") plus MITRE ATLAS AML.T0024.002 — model extraction is in scope, not only output disclosure.
Our Guardrails apply PII detection (SSN, credit card, email, phone number) and secret detection with configurable Block or Modify policies on input and output. GenAI App Observability adds Input/Output Guardrails, Session Tracking, and orchestration traces — extraction queries rarely look anomalous one at a time, but their session-aggregated trace does.
Audit-log signature: subcategory (PII / secret / business-data / sensitive-information-disclosure-llm event), action, masked value when Modify is used, session identifier for cross-request reconstruction.
Standards anchor: NIST AI 600-1 MP-4.1-001 requires periodic monitoring of AI-generated content for privacy risks; the UK ICO guidance on AI and data protection expects DPIA and Article 22 evidence for automated decisions with legal effect.
LLM03 Supply Chain
LLM03 covers compromised model weights, third-party fine-tunes, dependency chain risk, and base-model provenance. By the time a poisoned weight reaches a request, the supply chain failure has already happened — we do not natively enforce LLM03 at the runtime plane.
The compensating control is supplier management and model registry hygiene under NIST AI 600-1 GV-1.2-002, which requires policies that evaluate risk-relevant GAI capabilities prior to deployment and on an ongoing basis. ISO/IEC 42001:2023 applies a Plan-Do-Check-Act methodology; supply chain provenance belongs in Plan and Check.
What to require (of any vendor): documented model registry, signed model artifacts, base-model SBOM equivalent, and an incident response process for upstream compromise disclosures.
LLM04 Data and Model Poisoning
LLM04 is the training-time analog of LLM03. EU AI Act Article 15(5) requires high-risk AI providers to implement technical measures against data poisoning and model poisoning, alongside adversarial examples and confidentiality attacks. The ENISA Multilayer Framework places these in the AI-specific cybersecurity layer.
Like LLM03, this is not a runtime control surface. The compensating evidence is training-pipeline provenance plus model evaluation against poisoning red-team prompts — work that lives in the orchestration-tier Automated Evaluations of our GenAI App Observability stack as post-deployment drift detection, not as prevention. An AI red teaming program is the discipline that produces the evidence.
LLM05 Improper Output Handling
LLM05 covers downstream systems consuming LLM output as trusted — XSS, SQL injection, command injection, or code execution from raw model output. Our Guardrails include code-injection detection and an output-filter tier with the same Block / Modify policy plane. The decision lives on the response boundary, before the orchestration layer hands output to a downstream system.
Standards anchor: NIST AI 600-1 MS-2.7-001 lists bypass and extraction concerns; LLM05 detections are the runtime evidence trail.
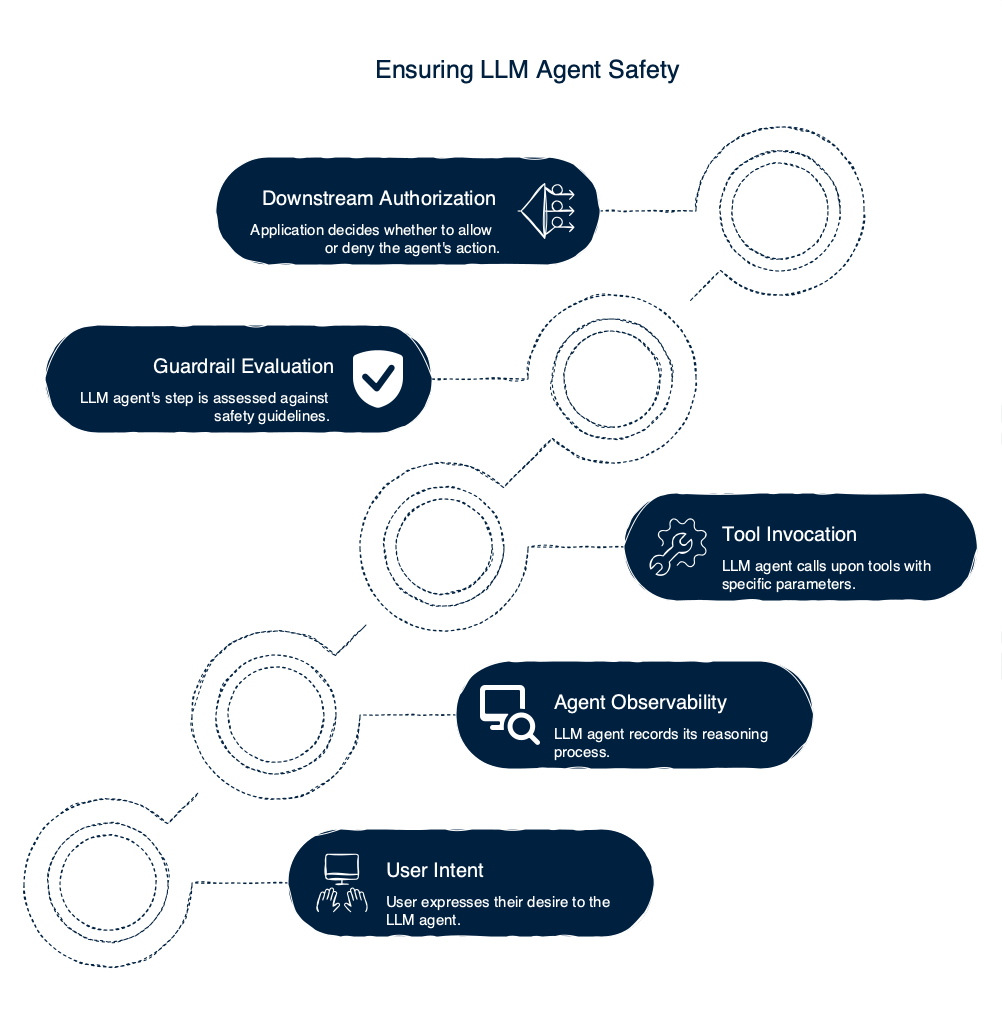
LLM06 Excessive Agency
LLM06 attributes the failure to three structural root causes — excessive functionality, excessive permissions, and excessive autonomy. OWASP's mitigation list singles out complete mediation (authorization in downstream systems rather than the LLM deciding whether an action is allowed) and minimize-extensions guidance limiting the agent's tool surface. The canonical OWASP example is an LLM personal-assistant granted mailbox access, where an attacker hides instructions in an incoming message that cause the agent to forward sensitive mail.
LLM06 is the cleanest argument against runtime-only thinking. Our Agent Observability exposes multi-step reasoning traces — the right telemetry to detect scope drift across steps, where an agent escalates from "summarize" to "forward" within a session. But traces cannot revoke an over-privileged extension. Downstream authorization is the load-bearing control: we surface the agent decision and your application enforces the permission. That is structural, not a tooling gap more telemetry will close.
Audit-log signature: per-step reasoning trace, tool invocation list with parameters, downstream authorization decision.
LLM07 System Prompt Leakage
LLM07 is the class where attackers extract the system prompt, exposing protected logic, key references, or guard text. Our Guardrails detect leakage attempts on the output boundary with the Block / Modify action plane. Require an audit log of detection events plus an inventory of where system prompts contain anything sensitive enough that leakage matters — system prompts containing no secrets are the first line; detection is the second.
LLM08 Vector and Embedding Weaknesses
LLM08 covers retrieval pipeline failures — poisoned embeddings, cross-tenant leakage in shared vector stores, prompt injection via retrieved documents (the indirect-injection overlap with LLM01), and inversion attacks on embeddings. Indirect prompt injection in retrieved context is covered by our Guardrails at the retrieval boundary. Vector-store hardening — tenant isolation, embedding integrity, access control on the vector database — is outside the runtime guardrail plane and belongs to retrieval infrastructure.
What to require: documented tenant isolation, embedding-integrity checks, and retrieval-time access control — none of which a runtime guardrail vendor supplies on your behalf.
LLM09 Misinformation
LLM09 covers hallucination, ungrounded outputs, and overreliance failures. Synchronous hallucination detection has high latency and limited accuracy on the request path, so our coverage centers on App Observability — Automated Evaluations, end-user feedback, and orchestration-tier distributed tracing that surface drift across model versions and prompt revisions. Treat LLM09 as an evaluation-loop problem with runtime signals, not a request-path block.
Standards anchor: NIST AI 600-1 GV-1.2-002 requires continuous evaluation; observability is the executable form of that obligation.
LLM10 Unbounded Consumption
LLM10 covers cost runaways, model-extraction-via-volume, and resource-exhaustion attacks. The runtime control plane is the LLM gateway — request rate limits, token budgets, per-tenant quotas, anomaly detection on consumption. Our GenAI Risk Protection frames financial exposure against the EU AI Act maximum fine ceiling of €35M for the most serious prohibited-practice violations; gateway-tier consumption controls are the operational counterpart.
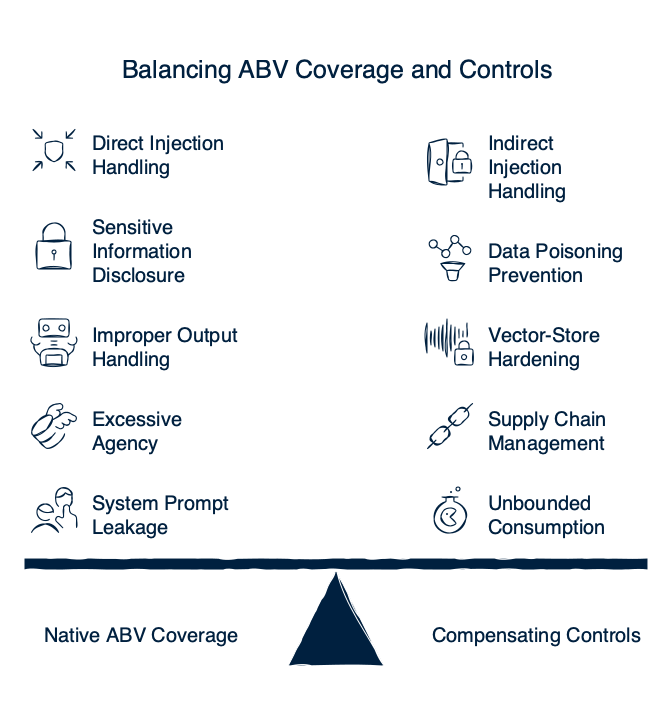
Where ABV's coverage stops
Three classes are not natively enforced at our runtime plane: LLM03 Supply Chain, LLM04 Data and Model Poisoning, and the vector-store-hardening side of LLM08. The reason is mechanical — LLM03 and LLM04 are pre-deployment integrity problems and the failure has already happened by the time a request hits a runtime guardrail. LLM08 splits cleanly: the indirect-injection-via-retrieval surface lives at the runtime boundary and we enforce it; the vector-database hardening surface belongs to the retrieval infrastructure and your data-platform team.
For a buyer choosing between governance-only platforms (Credo AI, IBM watsonx.governance), developer-tooling-first platforms (Helicone, Portkey), and pure runtime-guardrail platforms (Lakera), the question is which gaps are acceptable for your deployment shape. Governance-only platforms cover LLM03 and LLM04 documentation but not LLM01, LLM02, or LLM07 enforcement; pure runtime platforms do the inverse. Our stance is runtime enforcement plus orchestration-tier observability — but LLM03 and LLM04 still require upstream supplier and training-pipeline discipline that no runtime vendor supplies on your behalf. For a deeper treatment, see our companion guide on governance-only versus runtime-enforcement platforms.
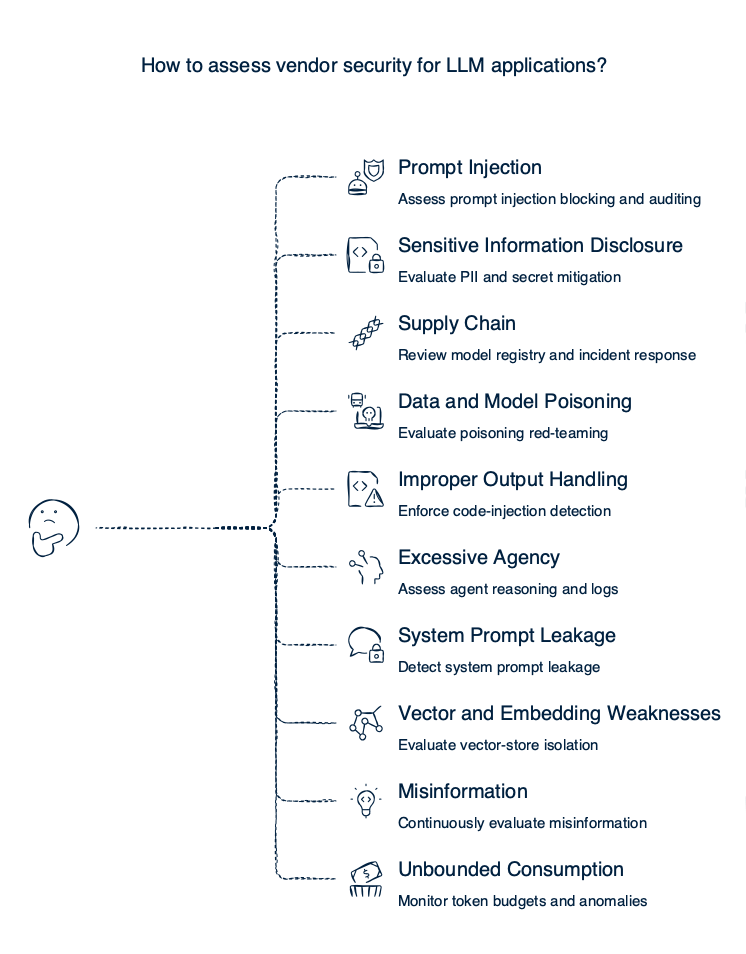
Vendor security review checklist for LLM runtime controls
Lift these into your RFP. They map directly to the criteria above and to OWASP LLM01-LLM10.
- LLM01: Are direct and indirect prompt injection blocked at input and retrieval, with per-request audit entries naming detection class and verdict? What is the latency budget per tier?
- LLM02: Are PII, secrets, proprietary algorithm exposure, and sensitive business data disclosure covered? Are Block and Modify configurable per category? How does observability support model-extraction investigation across a session?
- LLM03: Are model registry, signed artifacts, and a base-model incident response process documented? (Not a runtime question.)
- LLM04: Is post-deployment drift evaluated against poisoning red-team prompts? Is there an Automated Evaluations harness inside a documented AI red teaming program?
- LLM05: Are code-injection and improper-output-handling detections enforced at the response boundary before downstream consumption?
- LLM06: Are multi-step agent reasoning traces and tool invocation logs exposed? Is downstream authorization treated as load-bearing, with the vendor producing the decision signal?
- LLM07: Is system-prompt-leakage detection part of the output boundary? Where is the inventory of system-prompt contents reviewed for over-collection?
- LLM08: Is indirect injection via retrieved context enforced? What is the vector-store tenant isolation and embedding-integrity story, and which team owns it?
- LLM09: Does the evaluation harness run continuously, not only pre-deployment? Are end-user feedback and orchestration traces part of the GV-1.2-002 evidence trail?
- LLM10: Does the gateway expose per-tenant token budgets, rate limits, and consumption-anomaly detection? Is financial exposure quantified against EU AI Act maximums where applicable?
Two questions for any AI governance platform vendor: what is your ISO certification posture, and how do you evidence NIST AI RMF Measure and Manage? Our Trust Center reports ISO 27001 Certified and ISO 42001 Alignment — alignment, not certification. ISO/IEC 42001 was published in December 2023 and the accredited-certification footprint is small; alignment plus NIST AI 600-1 mapping is a defensible interim posture, and any vendor's claim should be precise about which it is.
Deployment shape and cost
Coverage depth depends on deployment shape. Vendors that promise uniform coverage across SaaS, VPC, and on-prem usually paper over a difference that matters. SaaS buyers get the full guardrail tier set, evaluations, and gateway controls as a managed service. VPC and on-prem buyers trade hosted-evaluation conveniences for sovereign control over inputs, outputs, and audit trails; the runtime plane runs in your environment and App Observability ships as a co-located control plane.
The cost driver buyers underestimate is not licensing — it is integration. Runtime guardrails that sit synchronously in front of latency-sensitive endpoints require engineering work to wire into your existing LLM gateway and orchestration layer. Budget for that integration and treat the guardrail license as the smaller line item. For SaaS / VPC / on-prem trade-offs, see our companion guide on AI runtime deployment shapes.
Recommendation paths
We are not the right shortlist entry for every AI security RFP, and a buyer guide that pretends otherwise is not useful. Use these recommendation paths.
- CISO at a B2B SaaS, AI, or DevTools company writing LLM features into the product: the criteria above are the scorecard. Runtime enforcement covers LLM01, LLM02, LLM05, LLM07; orchestration-tier observability covers LLM06 and LLM09; LLM03, LLM04, and LLM08-vector gaps live with supplier management, training, and the data platform.
- GRC function evaluating an AI management system rollout: the load-bearing question is ISO 42001 evidence and NIST AI 600-1 action coverage, with runtime controls as supporting evidence. Pair this guide with the governance-only-vs-runtime-enforcement companion.
- Hard ISO 42001 certified requirement today: treat any vendor reporting alignment — including us — as a non-fit until accredited certification matures. The standard was published December 2023 and the certified footprint is still small. Revisit in twelve to eighteen months.
FAQ
What does OWASP LLM Top 10 coverage mean in practice?
A meaningful claim is a per-class mapping showing runtime boundary, action policy, and audit-log signature. Without those three, "coverage" is a tick on a slide. OWASP LLM Top 10 is a taxonomy, not a certification.
How does this relate to ISO 42001 Annex A controls?
ISO/IEC 42001:2023 is a management-system standard; Annex A lists AI-specific controls organized around Plan-Do-Check-Act. Runtime guardrails contribute Do-and-Check evidence — per-request enforcement and audit signals. They do not satisfy Plan-and-Act alone.
What about EU AI Act Article 12 record-keeping?
Article 12 imposes automatic event logging on high-risk AI systems. The per-request audit signatures named throughout this guide are the runtime side of Article 12 evidence; orchestration-tier observability is the cross-session side.
How does NIST AI RMF Measure and Manage map here?
Measure (MS-2.7-001) and Manage (MG-family actions on incident response and risk treatment) are the action families a red-team or jailbreak program produces evidence against. Runtime telemetry plus orchestration traces are the executable form; "we map to NIST" without action IDs is not a mapping.
What should an LLM audit log contain at minimum?
For each event: request and session identifiers, detection class (mapped to OWASP), matched rule or model verdict, action taken, latency, and where in the orchestration the decision happened. Less than that leaves the reviewer reconstructing the event by inference.
How is this different from a generic AI governance platform comparison?
Governance-only platforms document the control; runtime vendors execute it on the request path. Both are necessary. A vendor security review for LLM risk should require evidence of both and treat either-without-the-other as a partial product.
The next step
If you want this mapping in a form your RFP can ingest directly, request access to our Trust Center for the per-attack-class checklist and supporting evidence. If you have a deployment-shape question — SaaS, VPC, or on-prem — book an implementation-planning conversation with our team rather than a generic discovery call. We will meet you at the procurement stage you are actually in.


