The choice between ABV and Credo AI is not about which vendor is better. It is about which platform class fits the operating model. Credo AI is a credible AI governance platform built around documentation, oversight, model inventory, and policy workflow. ABV is a runtime-enforcement-plus-evidence platform built around the GenAI request path, agent traces, and event-shaped audit records. For teams running regulated GenAI workloads, the architectural question is whether policy decisions need to be applied in-flight — before, during, and after a model request — or only documented for review afterward.
This comparison is most useful for CISOs, heads of AI/ML, AI risk officers, and platform engineering leaders who already understand the basics of AI governance software and are now triangulating between governance-only platforms, observability-only platforms, and the runtime-enforcement-plus-GRC wedge. We will define the decision criteria first, work through the comparison dimensions, then name where each platform class wins on its merits.
The decision behind any AI governance platform comparison
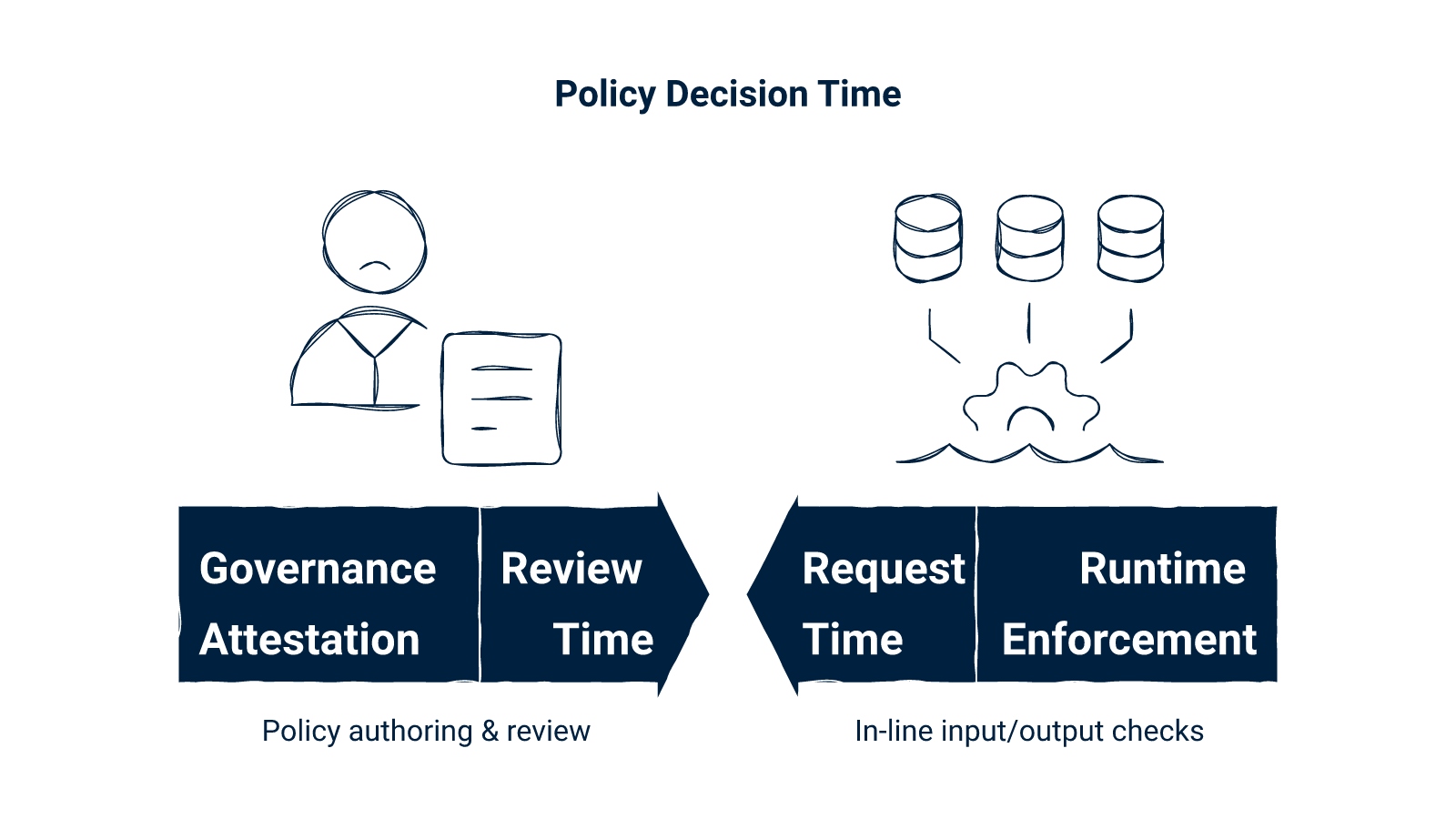
Most AI governance platform comparisons get confused because they mix two categories. Governance attestation answers documentation, oversight, and review obligations: model inventory, policy packs, risk reviews, sign-off workflows, and the audit narrative around them. GenAI runtime enforcement answers in-line request and response control: input checks, output checks, blocking, redaction, evidence capture, and the trace record around each call.
The same standards apply to both surfaces. The NIST AI Risk Management Framework Core organizes outcomes across GOVERN, MAP, MEASURE, and MANAGE — and explicitly does not prescribe a single mechanism for satisfying them. NIST positions the framework as voluntary guidance, not a binding standard, so adoption alone does not discharge regulatory exposure. Regulation (EU) 2024/1689 — the AI Act — Recital 66 is binding and lists obligations covering risk management, data quality, technical documentation, record-keeping, transparency to deployers, human oversight, and robustness, accuracy, and cybersecurity. Several of those — record-keeping, robustness, cybersecurity — are runtime-evidence problems, not policy-document problems. ISO/IEC 42001:2023 defines an AI management system on a Plan-Do-Check-Act cycle, which is policy-shaped by construction; how an organization satisfies the Check and Act phases is an implementation choice.
What changes between Credo AI and ABV is where the policy decision is made. With governance attestation, the policy decision is made at review time. With runtime enforcement, the policy decision is made at request time. That is the architectural axis. Everything else in this comparison follows from it.
The dimensions that matter in this comparison
We compare both options on the dimensions that drive procurement decisions for regulated GenAI:
- Policy authoring and governance workflow
- Model and application inventory
- Runtime AI guardrails and request/response enforcement
- Observability and trace evidence for agentic stacks
- Deployment model and data residency
- Standards mapping across NIST AI RMF, EU AI Act, ISO 42001, and OWASP LLM Top 10
- Third-party GenAI and shadow-AI coverage
- Audit-ready reporting and evidence shape
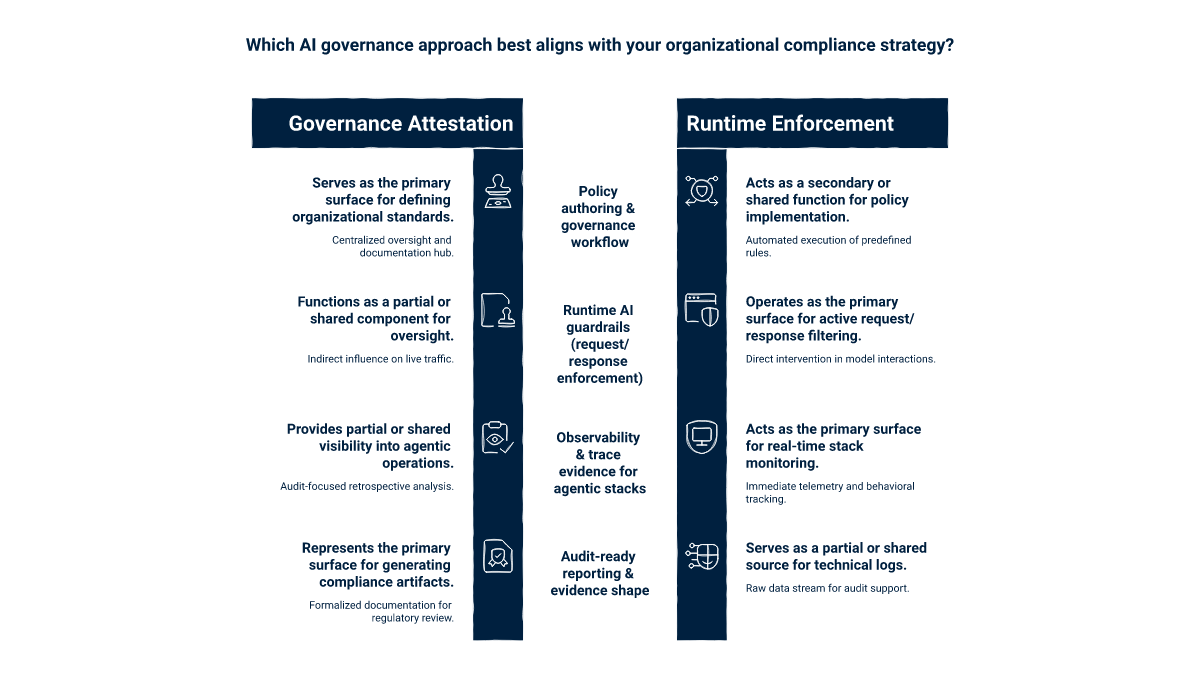
The first two dimensions favor governance suites by design. The middle four are where runtime enforcement carries weight. The last two are where the comparison ultimately turns, because evidence shape determines what auditors and regulators actually see.
Head-to-head: ABV vs Credo AI across the dimensions
Policy authoring and governance workflow
This is Credo AI's home territory. Governance platforms organize policy authoring, risk reviews, model inventory, sign-off workflows, and the audit narrative around them. They are useful for cross-functional review processes where legal, compliance, security, and business stakeholders need a shared system of record. ABV does not try to replace that workflow surface. We treat policy as runtime-applicable configuration rather than as a workflow object, which is a different representation of the same governance content. Teams that need a deep workflow-and-attestation layer should expect a governance platform to do that work better than any runtime-first tool, ABV included.
Runtime AI guardrails and request/response enforcement
Runtime is where the platform classes diverge. ABV positions guardrails as in-line enforcement that blocks unsafe or non-compliant outputs before they reach users, rather than monitoring AI behavior after the fact. The GenAI Guardrails surface sits in the request and response path so that input validation, schema and pattern checks, hallucination detection, toxicity, bias, and compliance checks can fire in-line. Governance platforms describe the policies; runtime AI guardrails apply them. A buyer evaluating a Credo AI alternative on this dimension is asking a different question — not “can you describe the rule” but “can you act on the rule at request time.”
Observability and trace evidence for agentic stacks
Modern GenAI deployments are increasingly agentic, which expands the surface where policy decisions need to be enforceable. ABV's agent observability integrates with OpenTelemetry, LangGraph, Bedrock, Strands Agents, and ADK to capture multi-step reasoning, tool calls, and autonomous decisions in production. The output is event-shaped evidence: spans, traces, blocked-call records, and decision audit trails tied to the underlying call rather than to a policy document. Governance platforms can ingest some of this telemetry for reporting, but they are not the system that produces it.
Deployment model and data residency
Regulated GenAI workloads usually have a hard residency constraint. ABV documents deployments across US (Virginia), EU (Ireland), and dedicated HIPAA regions, so that customer data stays inside a chosen region rather than crossing borders. The same overview describes ISO 27001 certification with annual third-party audits, plus ISO 42001 alignment for the AI-specific surfaces. Buyers should evaluate Credo AI on the same dimension, particularly when the GenAI workload runs in a sovereign region or under healthcare data rules. Residency is a deployment-model decision, not a feature flag, and it tends to be where comparisons quietly fail in procurement.
Standards mapping: NIST AI RMF, EU AI Act, and ISO 42001
For EU AI Act compliance specifically, the binding obligations live in Regulation 2024/1689. Recital 66 covers high-risk AI systems and bundles documentation obligations with robustness, accuracy, and cybersecurity obligations. Recital 115 requires general-purpose AI model providers, where a model presents systemic risks and a serious incident occurs, to track the incident and report relevant information and possible corrective measures to the European Commission and national competent authorities without undue delay. That last obligation is structurally a runtime telemetry problem. The OWASP Top 10 for LLM Applications (2025) is the operational counterpart: LLM01 Prompt Injection through LLM10 Unbounded Consumption define the request-path risk taxonomy that runtime AI guardrails are built to block in-flight. NIST AI RMF and ISO 42001 set the outcomes and the management-system frame. The standards do not pick a vendor, but they push the operating model toward both surfaces — policy and runtime — being instrumented.
Third-party GenAI and shadow-AI coverage
Discovery is a governance problem. Once a tool is in use, control becomes a runtime problem. Governance suites are well-suited to inventorying which third-party GenAI applications and which internal models exist. ABV's value on this dimension shows up after discovery: when a third-party tool is routed behind the LLM gateway, the same input and output checks can apply to its traffic. The comparison question here is not “which platform finds shadow AI first” but “which platform can enforce a policy on it once it has been found.”
Audit-ready reporting and evidence shape
This is the dimension that determines what auditors actually see. A governance platform produces policy-shaped evidence: that the right policy existed, was reviewed, was approved, and was scheduled for re-review. A runtime-enforcement platform produces event-shaped evidence: that the right action was taken on a specific request at a specific time, recorded as a span or trace. Both forms are valid. EU AI Act Recital 66's record-keeping requirement and Recital 115's serious-incident reporting requirement are easier to discharge from event-shaped evidence because the regulator is asking about specific occurrences, not about the existence of a control. Buyers should look at how each platform's evidence maps to the obligations they are most likely to be examined against.
Latency budgeting: what runtime AI guardrails actually cost
A common objection to runtime enforcement is latency. The shape of the latency budget tells you how realistic in-line control is for a given workload.
ABV's LLM gateway adds sub-1ms processing time per request with one network hop, and full guardrails can add 1-2 seconds of latency depending on guardrail type and placement. The published guardrail performance target is under 300 milliseconds for the typical end-to-end runtime check. The reason there are two numbers is that guardrails separate by cost class: rule-based pattern matching and schema validation run in under 10 milliseconds, while LLM-powered semantic checks for toxicity, bias, and hallucination typically take 1-3 seconds. The implication for architecture is that cheap rule-based guardrails belong ahead of expensive LLM-powered checks in the chain. That makes runtime AI guardrails a tunable trade-off rather than a black box: latency budget, guardrail mix, and placement are all choices the platform team controls. AI compliance automation that lives outside the request path does not face this trade-off because it does not participate in the request at all — which is also why it cannot stop a request.
Scenario fit: when each platform class wins
Most regulated GenAI deployments need both surfaces eventually. The useful question is where to start, given the team's current state.
A governance-only AI governance platform is the right fit when the binding obligation is documentation, model inventory, sign-off workflow, and risk-review cadence — for example, a financial-services team building an internal model inventory for an AI risk management platform program, or a public-sector team responding to procurement requirements that ask for a system of record. In those scenarios, runtime enforcement is a future quarter's problem and a governance suite is the cleanest entry point.
A runtime-enforcement platform is the right fit when the production GenAI footprint is the actual risk surface — when jailbreak attempts on production AI applications are a normal operational condition, when prompt injection or sensitive information disclosure has to be blocked at the gateway, when EU AI Act Recital 115's serious-incident reporting depends on event-shaped evidence, or when residency rules require an on-prem or in-region deployment of the control plane itself.
A Credo AI alternative is the right comparison framing when the team has already concluded that a workflow-and-attestation tool will not, on its own, discharge the runtime obligations they are exposed to. That is the buyer profile that finds ABV: a team that needs model governance, AI compliance automation, and the runtime AI guardrails surface together, with audit evidence shaped to the obligation rather than to the policy.

When ABV is the Credo AI alternative to evaluate
We do not position ABV as a replacement for governance attestation in every deployment. We are the runtime control plane: input and output validation, hallucination and safety checks, agent trace and span evidence, gateway-mediated third-party GenAI control, and the regional deployment posture to keep all of it inside the boundary the workload requires. If those are the binding obligations on the team, the comparison is no longer “ABV vs Credo AI” — it is whether the team has both classes covered.
FAQ
What is the difference between AI governance and runtime enforcement?
AI governance is the documentation, oversight, and review layer: model inventory, policy authoring, risk reviews, and the audit narrative. Runtime enforcement is the in-line layer that acts on the GenAI request and response path itself: input checks, output checks, redaction, blocking, and event-shaped evidence capture. They are complementary categories. Most regulated GenAI workloads need both, with the runtime layer carrying the obligations that depend on what actually happened on a specific request.
Is Credo AI enough for runtime AI guardrails?
It depends on where the binding obligation lives. Credo AI is a credible governance platform, and for documentation and workflow obligations it is a reasonable fit. For obligations that depend on stopping a request in-flight — prompt injection, sensitive information disclosure, improper output handling — buyers should verify against Credo's current product documentation whether the native enforcement surface meets the team's request-path requirements, or whether a separate runtime control like ABV is needed.
Can AI governance tools block unsafe GenAI requests?
That depends on whether the platform participates in the request path. A pure governance suite that lives outside the request path can describe the policy and report on what happened later, but cannot block the request in flight. Runtime AI guardrails sit in the request and response path so that the same policy can be applied before, during, and after the model call. The distinction is architectural, not philosophical.
How do AI governance platforms support EU AI Act compliance?
Governance platforms support EU AI Act compliance on the documentation, oversight, and record-keeping obligations under Recital 66 of Regulation 2024/1689. They do not, on their own, satisfy the robustness, accuracy, and cybersecurity obligations, or the GPAI serious-incident reporting obligation under Recital 115, both of which depend on event-shaped evidence from the production system. Most teams subject to the AI Act will need governance attestation and runtime enforcement together.
When should a company choose ABV over Credo AI?
When the obligation is operational rather than documentary. If the team needs to block prompt injection at the gateway, capture agent traces with OpenTelemetry, LangGraph, Bedrock, Strands Agents, or ADK integration, keep audit evidence inside a US, EU, or HIPAA region, and present event-shaped records to auditors and regulators, ABV is the comparison to run. If the binding obligation is workflow and attestation only, a governance suite is the cleaner starting point.
Next step
If the comparison points to runtime enforcement, the practical next move is to scope the request-path coverage you actually need. The GenAI Guardrails page lays out the runtime guardrail categories, performance budget, and chaining patterns. The GenAI Risk Protection page frames the protection scope for production GenAI applications. The Security and Compliance overview covers deployment regions, certifications, and the controls auditors most often ask about. A short scoping conversation usually gets a team from “we think we need runtime enforcement” to a clear evaluation plan.


